








Distributed Databases
Redis for hot cache; Cassandra/CouchDB for large datasets… What if there was DB that can do it all?
Choosing a database for your next great thing is hard — as in “hard to guess where your project will take you”, and switching databases is even harder. My personal go-to strategy is the “right tool for the task”, hence I can end up with several.
But what if there was a product that was hybrid enough to suit multiple workloads? There is a grain of truth in saying, “Jacks of all trades are masters of none”, however, I recently had a quick deep-dive into the Apache Ignite database and I think we may have that “master of all”.
.elementor-widget-theme-post-featured-image {
display:none;
}
 Apache Ignite — a master of all trades?
Apache Ignite — a master of all trades?
Can it replace Redis?
Or Hazelcast? Benchmarks say it can. It’s a RAM-first distributed cache. It scales natively by breaking data into partitions and distributing them between cluster nodes with automatic rebalancing.
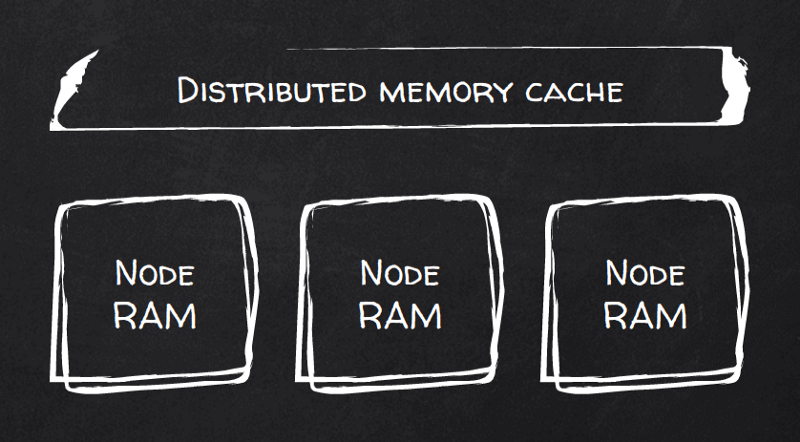
Clients can connect to any node to run queries, but best of all, clients can connect to all nodes and use simple math to query the right node for every given key. I.e., directly reach the node that contains local data for a given key.
Persistence?
Check. Flick persistenceEnabled flag (though with 8 lines of XML config) and your RAM is now persistent. In fact, Ignite calls it “Durable RAM”.
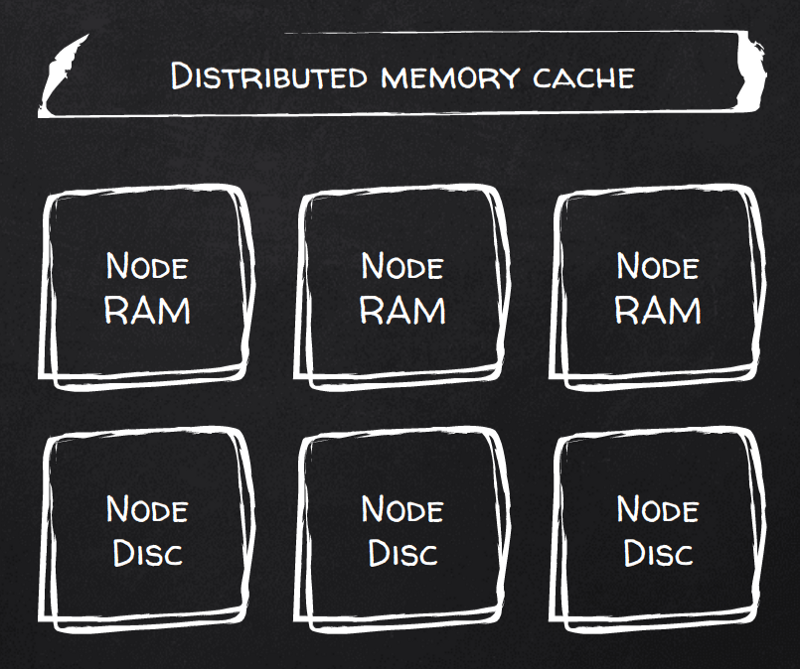
Now every document write will be persisted. You can control the number of copies (replicas) as well as a level of write consistency — from a weak consistency where writes are ack’ed after being written to buffer cache on the first (primary) copy to strong consistency when your writes are guaranteed to be fsync’ed on every replicated nodes before acknowledging them to a client.
It begs me to call it “Redis done right”. If you ever explored the Redis cluster setup, you’ll know what I mean.
Beyond key/value
Many will argue that a comparison between Redis and Apache Ignite is not fair. After all, Apache Ignite can provide much more than key/value including:
- Transactional multi-key operations
- ANSI-99 SQL support including distributed joins
- Grid Computing — load your jar into Ignite and blur the line between compute and storage in favor of data locality
- Data Streaming
“Cool, but that’s expensive!”
Sure it is. Performance costs money, but at least in this case money can buy you performance.
But maybe I don’t need that performance, at least not on day one. Can I pay as I go? Indeed! This is where this project got my full attention when I started exploring it on behalf of our client.
All you need to do is drop Memory/Disk ratio as low as you want and performance will go down together with cost. In fact, this is what I was looking for — a cheap key/value store with adequate performance.
It works as simple as you could’ve imagined — Ignite fits into RAM what it can, and the rest goes to disk. It automatically manages that hot RAM cache. Interestingly enough, Ignite considers itself memory-first, hence, writes are first put in RAM before being persisted to disk; that is, freshly written data effectively becomes hot data, for the good and the bad of it.
How cheap can it get?
To test, we ran benchmarks on GKE (Google-managed Kubernetes cluster) with 4 nodes across 2 zones, 1 primary and 1 replica copy for each cache partition; each node had 2 vCPUs / 16GB of RAM, and 1TB SSD persistent disk attached. That’s just ~$250 per TB per month!
We managed to put 200 million 512 char long docs at 7,465 writes/sec with a median latency of just 1.59ms. That’s without deep-diving into performance tuning like a smart client that knows which node to talk to for every key request.
After having initial data in we tried to simulate a daily load pattern having 9 thin clients doing random inserts, updates, and read all together with the following results:
- 3,682 inserts/s, 3.8ms median latency
- 4,229 updates/s, 4.8ms median latency
- 3,952 reads/s, 4.2ms median latency
The number may not look impressive, but look at the value — 4TB key/value DB for ~$1000/month with single-digit milliseconds response latency - it’s a steal!
This workload was totally CPU bound, but $170 out of $250 per-node/per-month you pay for storage. So doubling CPU/RAM capacity will bring the cost to ~320$/month per TB, and I wouldn’t be surprised to get close to double performance gain [speculation warning here].
If that wasn’t cheap enough, out of curiosity we’ve tried using standard (i.e., magnetic) persistent disks, bringing the total cost of TB down to $120/month. It still cranked 3,800 doc/sec on random gets with 3.2ms mean latency (no inserts or updates, just reads). Though I wouldn’t recommend this setup for production workloads.
Silver bullet?
So far it may look like Ignite is “the best thing ever!”. But once you start using it, rough edges start to show up. Like the difference between tourism and immigration :)
Let’s look at both Dev and Ops as part of the equation.
So how is Dev?
If you are a native Java/Spring citizen you’ll feel at home. And many things indeed seem to be available for Java only, like Streaming or Grid Computing.
There are clients for other languages but you’ll feel a bit like a foster child — officially you are part of the family, but are you really? Documentation is very very Java-centric.
Take a REST API for example — a closer look reveals that it’s more of HTTP RPC than a real REST API (as in object collections + CRUD). Typical REST API call looks like:
GET /ignite?cmd=getorcreate&cacheName=test-cache
But even that is limited in scope. For instance, to get partition metadata for a given cache, you need to fancy the following request:
GET /ignite?cmd=exe& name=org.apache.ignite.internal.visor.compute.VisorGatewayTask& p1=nid1;nid2;nid3& p2=org.apache.ignite.internal.visor.cache.VisorCachePartitionsTask& p3=org.apache.ignite.internal.visor.cache.VisorCachePartitionsTaskArg& p4=my_cache
Neat, ah? And I had to employ sniffing HTTP proxy to fish that out.
And Ops?
Many rough edges as well. We ran it on GKE and there are official guides to do so, but I would not consider them production-ready. We made many improvements including:
- Multizone-setup with zone-awareness out of the box. E.g. all primary copies will reside on nodes in zone A and replicas on nodes in zone B.
- One Ignite pod per node. You better not mix Ignite with other workloads in your cluster.
- Node configuration through K8s ConfigMap instead of being pulled from GitHub.
- No dedicated disk for WAL — in GCP disk performance depends on size so having a fast and large dedicated disk is a waste of money.
All our improvements are available in the following GitHub repo: https://github.com/doitintl/ignite-gke
But there are more hardships, unfortunately:
- I couldn’t get IgniteVisor (the CLI tool) to connect to the cluster. It is asking for an XML config file(!) when opening a connection, and none of those I provided worked, even when running it locally on the Ignite node.
- Not much luck with Web Console either — running it requires launching web-agent, web-frontend, web-backend, and MongoDb(!) pods. But the worst part is that docker images for web-* part are lagging behind and are a year old. Trying to build them myself I found out that Dockerfiles are not self-contained and require a local build first.
- Configuration requires you to write, or rather copy/paste very verbose XML. Enabling just a simple boolean property requires 8 lines of XML and looks like this:

- There seems to be no way to back up the Ignite cluster unless you use a commercial subscription from GridGain. Simply making disk snapshots may leave with inconsistent WALs between primary/replica nodes unless you use e.g. Amazon EBS crash-consistent snapshots. Even then restoring them is quite tricky since Ignite embeds node IDs in persisted data and new nodes will need to match those. One of the developers told me that the snapshot feature is coming into open-source addition soon.
And the verdict is?
The technology is very interesting. You can indeed use it as a do-it-all tool and run both fast/expensive and slow/cheap workloads, even on the same cluster.
However unfriendly tooling and lack of backups make it hard to recommend this tool for production use, which is unfortunate considering many of its great features.
I only hope those shortcomings will be rectified in the near future so that we could enjoy Ignite’s greatness in full.
And if you want to play with today on GCP, our ignite-gke GitHub repo will help you to start quickly.
Finally, it will be really interesting to see Ignite tested by Jepsen to find out how good are their consistency guarantees in practice.



