









Edit: This article is written specifically for Airflow 1.X running on Cloud Composer. Since writing Google has released Airflow 2.X in preview mode on Composer and I have written this article which updates the code used in this article to Airflow 2.X. I recommend going through this article first then reading the other.
Here at DoiT International, a very common support ticket we have gotten lately is how to run containers on Cloud Composer (managed Airflow) effectively.
Since Cloud Composer runs on top of a Google Kubernetes Engine (GKE) cluster, this allows for massive scalability and working around the limitations of the other managed Airflow services out there.
While doing a quick search shows the KubernetesPodOperator as being the solution, there are some “gotchas” that come along with that especially when running it on Cloud Composer.
This article clears that up and gets you running your DAGs (Directed Acrylic Graph) with containers in an efficient manner.
The Crux of KubernetesPodOperator on Composer
The KubernetesPodOperator class is the method of running containers on Cloud Composer, but it has one major flaw: it runs all containers on the same nodes as the DAGs running on Airflow. This means it’s competing with them for resources.
This may not sound so bad, but there are scenarios that could cause problems for you. For example, one of our customers started getting exceptions on running containers inside of a DAG because their other DAGs were using too much memory.
The underlying GKE cluster was unable to schedule additional DAGs and tasks so Airflow just started throwing a timeout exception when trying to run any KubernetesPodOperator task. Due to this, their mission-critical DAG that contained a container was unable to run. If this had been a DAG that calculated payroll or bonuses for the year-end then it definitely would’ve been a major problem with serious implications.
This brings us to the solution to this particular issue, but first a few small explanations on how GKE works. If you are familiar with GKE then feel free to skip the next two sections and get straight to the solution.
Enter Node Pools
For those unfamiliar with GKE or managed Kubernetes environments, the group nodes together into a group called node pools. When pods and workloads are scheduled, they are executed on one or more nodes contained inside of the associated node pool. A cluster can and often does have multiple node pools.
When a Cloud Composer instance is created, it creates a GKE cluster with a single node pool containing the configured size and number of nodes. This node pool by default runs all DAGs and their associated tasks, in addition to all of the services created and orchestrated by the Cloud Composer instance (except for the backing MySQL database).
Since this node pool contains a pre-configured quantity of nodes and instance sizes, resources will be limited and very finite here. Note that there is an autoscaling feature available here, but at the time of writing, you cannot change the size of nodes. As a result, it will only add more of that same-sized instances to your node pool. If you have a task inside of a DAG that requires more memory than a node allows then it will more than likely lead to the exception issues described above.
So, how do you fix this? Create a node pool that is dedicated to running tasks that contain containers. If you are familiar with Kubernetes, then the issue of affinity will come to mind. That’s exactly the solution to this problem and why, at the time of writing, we can only perform this on tasks running containers.
How Scheduling and Affinity work
Scheduling
As mentioned above, Cloud Composer runs on top of a GKE cluster with all of the DAGs, tasks, and services running on a single node pool. When a DAG is executed, a service inside of Airflow called the scheduler creates an execution plan on the order tasks will be executed in.
When execution of a DAG starts, the scheduler readies each task for execution on service inside of Airflow called the worker. When the worker is ready to run the task it tells the underlying Kubernetes service to execute the task. In the process of this, Kubernetes does a lot of processing, determining if there are resources available to execute the task. It also decides on which node in the node pool to execute the task on.
By default, it will run this task on whatever node in the Cloud Composer-created node pool that the system feels is the best candidate. Depending upon the size of the Airflow instance this can be quite a few DAGs, all with a large number of tasks running in them being scheduled at once on the same node pool. This creates some competition for the finite resources available in the node pool.
Affinity
One solution you might decide on is to run certain tasks on a dedicated node in the node pool only and nothing else on that node. The process of making this happen is called affinity and the opposite called anti-affinity.
Affinity works by applying a label to specific, or all, nodes in a node pool. When creating the definition of a task inside of a DAG, a construct called a nodeSelector is used which instruct the underlying Kubernetes cluster to run that task only on a node that has a matching label.
Anti-affinity follows as the opposite, saying “do not run this task” on a node that matches a specific label. This makes it possible to schedule certain tasks on certain nodes and not others, which allows for a specific distribution of the workload.
If you are curious how this works under-the-hood, the Kubernetes specifics of doing this can be found here.
Combining KubernetesPodOperator and Node Pools
In order to solve our aforementioned issue, we will be combining the KubernetesPodOperator, a new and dedicated node pool to run these tasks, and Kubernetes affinity. This ensures your containers run in a separate “sandbox” where resources aren’t constrained by what you selected when you created the environment.
The code I will be referencing is located on Github here.
Inside of the sample_dag.py file is a DAG that has a structure like this:
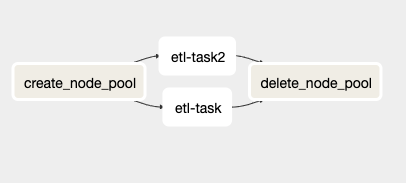
In this DAG are four different tasks, two of which (etl_task and etl_task2) are duplicates and will be replaced by any end-user to run their code.
The create_node_pool task is a BashOperator that will pull in some pre-set environment variables (more on this in a later section), creates a new GKE node pool, and stores the name of that node pool inside of an Airflow variable. The last step is required because the KubernetesPodOperator does not allow environment variables to be used inside its affinity argument.
The etl_task and etl_task2 tasks are sample tasks that I created to show the KubernetesPodOperator in action. They will start up an Ubuntu 18.04 container and sleep for 120 seconds before shutting down. The key part of these tasks though is in the code. It shows how to set up the affinity for the operator which tells your GKE cluster to schedule the container on the newly-created node pool. I will cover this in more detail in the next section.
The last task, delete_node_pool, is a BashOperator that deletes the created node pool upon completion (or erroring) of the rest of the DAG. One thing to note is that this task will always run even if other tasks return error codes, this is so you will not have a running node pool racking up costs unexpectedly due to an error.
Breaking Down the KubernetesPodOperator Code
Here is a copy of the etl_task code from the python file below with the comments and a few lines removed from it that are not very important (i.e. the sleep commands):
etl_task = kubernetes_pod.KubernetesPodOperator(
task_id='etl-task',
name='etl',
namespace='default',
image='gcr.io/gcp-runtimes/ubuntu_18_0_4',
startup_timeout_seconds=720,
affinity={ 'nodeAffinity': { 'requiredDuringSchedulingIgnoredDuringExecution': { 'nodeSelectorTerms': [{ 'matchExpressions': [{ 'values': [ Variable.get("node_pool", default_var=node_pool_value) ] }] }] } }
})
You will notice that I bolded the affinity object parameter above, which is what I am wanting to focus on here because it’s very Kubernetes specific.
What this code is doing is telling Kubernetes, when scheduling (versus executing) this task, to require it to schedule onto a node with a label that matches the name of the node pool created by the create_node_pool task. It does this using a nodeSelector and tells it to match a label with the name of the created node pool. When GKE creates a new node pool, it automatically applies a label with the name of the node pool onto each node in it, which is what we are matching against in this code above.
One thing to note is that it pulls the label value from the Airflow variable node_pool. If you run multiple instances of this DAG, then I recommend changing this variable name to be DAG specific. Just be aware that due to limitations in Airflow you cannot put any templates or dynamic code (such as pulling an environment variable) into the affinity parameter object or else it will fail to load the DAG.
Configurable Items for DAG
Since this code is creating a node pool that isn’t one-size-fits-all for everybody, I have introduced a few environment variables into the code to allow changing of options related to the node pool.
Here is the list of environment variables and their functions:
NODE_COUNT
This is the number of nodes that will be provisioned inside of the new node pool. The default value is 3.
MACHINE_TYPE
This is the instance type (size) of a virtual machine that will be provisioned inside of the new node pool. If you’re using this for shorter-running workloads and you are removing the node pool upon completion then I highly recommend using the E2 machine types since these already have the sustained-use-discount built into the price so therefore are cheaper for short-lived workloads. The default value is e2-standard-8 (8 vCPU and 32GB of RAM).
SCOPES
This contains the GCP scopes that are attached to the instances in the node pool. For instance, allowing access to BigQuery and Pub/Sub as well as being able to write logs would have the following scopes: bigquery, pubsub, logging-write. The default value is default,cloud-platform.
Conclusion
This was a very simple way of running containers inside of a DAG on Cloud Composer. It’s not the easiest route to take, but unfortunately due to the limitations imposed by managed services, sometimes steps like these must be performed until the provider implements a first-party solution to perform this natively.
I for one would love to see the ability to specify affinity for more than just KubernetesPodOperator tasks because sometimes tasks other than container-based tasks can cause these issues, namely python or bash operator tasks.

Thanks for reading! To stay connected, follow us on the DoiT Engineering Blog, DoiT Linkedin Channel, and DoiT Twitter Channel. To explore career opportunities, visit https://careers.doit.com.



