








Meet Banias — high performance analytics pipeline built on top of Kubernetes, Apache Beam and Google BigQuery
Here, at DoiT International, we are working with quite a few startups. All of them know that having a reliable data is vital to their success. Plenty of them are approaching us with the question how to build an analytics pipeline to analyze user’s behaviour.
Building on our past experience with companies such as Jelly Button and Rounds, we have built Banias — an opinionated serverless event analytics pipeline based on Kubernetes, Apache Beam and Google BigQuery.

Banias (Arabic: بانياس الحولة; Hebrew: בניאס) is the Arabic and modern Hebrew name of an ancient site that developed around a spring once associated with the Greek god Pan. And like the flow of the Banias, events are flowing into our system from users to Google BigQuery. As a concept, we have decided to build a reference architecture and actual implementation of event analytics pipeline. You can take the code as it is and use it or use it a design reference.
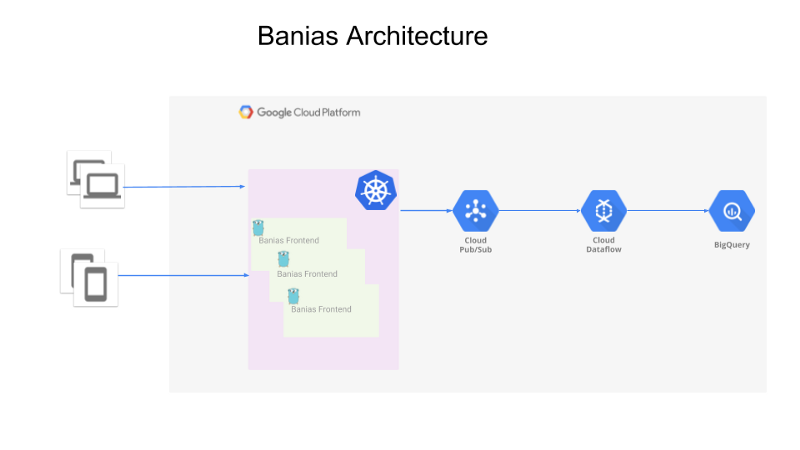
The general architecture is as following:
- API that receives the events from the producers (could be web apps, mobile app or backend servers)
- The events are sent to Google Pub/Sub
- Apache Beam running on Google Cloud Dataflow is reading the events from Pub/Sub and sending them to Google BigQuery for analysis.
Events API
The front end is written in Golang and is running as a service inside a Google Kubernetes Cluster. It receives a payload in the following format:
Each request can have one or more events:
{
"sender_id": "my id",
"events": [
{
"type": {
"event_version": "16",
"event_name": "transaction"
},
"payload": {
"action": "buy",
"price": 170,
"date": "1967-03-31"
}
},
{
"type": {
"event_version": "64",
"event_name": "click"
},
"payload": {
"screen": "welcome"
}
}
]
}
A payload field is just a json object which allows the user to define his event structure. The app does some basic yet necessary validation of the structyure; then it will add to each event the id and will queue it into a Golang’s buffered channel. There are workers that are listening and the channel and are dequeuing the events and sending them to Google Pub/Sub.
We wanted to create an app that can handle a large number of requests in an cost efficient manner. Our API can handle about 14,000 requests per second (each request may have up to five events) running on a single two core node in the Google Kubernetes Engine cluster.
In the app we carefully selected to use performance oriented libraries such as fasthttp, ffjson, jsonparser and zap and also using workers pools and sync pool so we can squeeze a lot of performance from our our servers.
To monitor the app we are exporting data to Stackdriver and Prometheus via OpenCensus (You can read more about it in this blog post). If you would like to use Prometheus, we would recommend to install it using Prometheus Operator using this script.
Backend
In order to process the events and insert them into BigQuery we are utilizing Cloud Dataflow. Cloud Dataflow is a fully-managed service for transforming and enriching data in stream (real time) and batch (historical) modes with equal reliability and expressiveness. We are using Java based SDK from the latest Apache Beam SDK v2.4.0
Banias aims to provide an easy way to ingest events into Google’s BigQuery with the ability to have new schemas as events evolve with minimum code changes. To achieve this we are using Apache Beam on top of Google’s Cloud Dataflow as our backend engine.
The code is a baseline for any transformation graph you would like to create in the future. You can always extend the BaseMap or the MapEvents to get some funky stuff into the graph :-).
BigQuery allows you to specify a table’s schema when you load data into a table, and when you create an empty table. When you specify a table schema, you must supply each column’s name and data type. You may optionally supply a column’s description and mode.You can find more information about schema and schema creation here.
Banias utilize the standard schema format used by Google’s BigQuery. You can find sample schemas can be found under the test folder.
Errors are written into an Error table. In the table you will find all the elements that had issues (not having a schema is not an issue…). The error table contains the the event type, content and the error that got this event to the error table.
Running the pipeline:
make run PROJECT_ID=my-project DATASET_NAME=important-dataset TOPIC_NAME=topic-name SUBSCRIPTION_NAME=subscription-name SCHEMAS_BUCKET=bucket-with-my-schemas TEMP_BUCKET=mytmpbucketYou can start using Banias as it is with your own schemas, or you can you it as a blueprint or a starting point for building your own customize data pipeline
Want more stories? Check our blog, or follow Aviv on Twitter.



