








 Use CloudRun and Eventarc to monitor and automate actions on your GCP projects.
Use CloudRun and Eventarc to monitor and automate actions on your GCP projects.
Late last year, Google very low-key announced a new service called Eventarc. They described it as an event-triggering functionality built into Google Cloud Platform, based upon CloudEvents. It is very similar to AWS’s CloudWatch Events functionality.
It was just released as GA a few days before the time of publishing this article, it‘s a very powerful feature that is not well known yet. Eventarc has a lot of potential for organizations wanting to perform more automation or needing more monitoring of their resources.
Since this is very much an unknown service, I wanted to expand upon their quickstart and show how to use this service with a practical example to highlight what is possible.
Explanation of the Service
Google’s quickstart on this receives Cloud Storage events, which is a very handy service for notifying when data is changed and used very often by Cloud Functions to do something when an object is created, updated, deleted, etc. It also acts as a very good starting point for using Eventarc.
To expand upon Google’s quickstart, I am adding the functionality to automatically load files created in a GCS bucket into BigQuery, a very common request we get here at DoiT International.
The service I am using in this article will be triggered by the creation of a new CSV file inside of a GCS bucket and will perform a load job of that file into a BigQuery table.
Note: Eventarc is still a new product fresh out of beta so there is some missing functionality, the largest of which is targeting specific resources. This requires the code triggered to check and determine if it is the correct resource or not, which is performed in my code for this article.
Building the Image
The first step will be cloning a repository containing code I have written for this article, and then submitting it to Cloud Build to create a container image for use by Cloud Run.
First, you will need to open up Cloud Shell inside of your GCP Console. Make sure it is set to the project you are wanting to use by running the following command and substituting in your project ID for <project id>:
gcloud config set project <project id>
Once the correct project is set, run the following command to clone the git repository:
git clone
https://github.com/sayle-doit/eventarc-blog.git
cd eventarc-blog
After you’ve completed the cloning, I would advise taking a look at the code — specifically, the Dockerfile and main.py files — in there just to see what this is doing.
Next, a container image needs to be built from this Dockerfile. Run the following command in Cloud Shell and substitute in your project ID for <project id>, as well as a good container image tag for <tag>. This can be anything you want as long as it is unique from other tags in the project:
gcloud builds submit --tag gcr.io/<project id>/<tag>
This should take about 30–60 seconds to build and will return a success message with a build ID.
Take note of the tag you used, as that will be used in the creation of the Cloud Run service in the next section.
Security Notes
In the next two sections, I will be using some options which are NOT a best practice for a production environment. Securing the environment goes well beyond the scope of this article. In this article I am just demonstrating a setup for you to recreate to learn and test the services in a controlled environment so please run this in an isolated and non-production GCP project to start with.
First I will be using the default service account, Compute Engine default service account, when creating resources. I highly recommend not using this method in a production environment. You should create a specific service account using the principle of least privilege applied to it when creating these services as a best practice.
Secondly, I am using environment variables to store runtime data for simplicity’s sake. In a production environment, there is a very good chance that there will be sensitive data used by the Cloud Run service. I would highly recommend for a production workload to use a more secure method of storing this data such as GCP’s Secret Manager or HashiCorp’s Vault product.
Creating the Cloud Run Service Overview
I am using the command-line to create the Cloud Run Service here due to Eventarc being a new service and the UI for it is changing very rapidly so there is a very high chance any screenshots of it will not reflect how it will be within a month or two of the time of writing.
With that said since this is a new service, things might change on the command-line without any sort of notice as more features are added, but the command-line historically changes much less often than the UI.
All of these will be run inside of your Cloud Shell inside of the Google Cloud console unless you wish to do this in your own terminal. In both cases please ensure you have the latest version of the Google Cloud SDK CLI installed since most of the commands below exist only in the newest versions as of the time of writing. To do this run this command and select yes when prompted to update:
gcloud components update
Creating Environment Variables
The first step will be to create some environment variables to be used by the create commands below. Since Eventarc and Cloud Run use different region name definitions and formats I have separated those out into two different variables.
Here is a quick summary of each variable:
TAG_NAME: Container Image tag you specified on your Cloud Build submit command earlier
CLOUD_RUN_SERVICE: Service name used for the Cloud Run service created
CLOUD_RUN_REGION: region the Cloud Run service will run in
BUCKET_NAME: Name of the GCS bucket being monitored
BQ_TABLE: Full BigQuery table name with the project and dataset included (i.e. project.dataset.table). Note this value MUST be in this format or it will error out.
TRIGGER_NAME: Name for the Eventarc trigger.
TRIGGER_LOCATION: Google Cloud region the trigger will monitor the bucket in. If you are using a multi-regional bucket and wish to monitor it all use the string global in here instead.
Substitute in your values and run the following commands:
TAG_NAME=<tag> CLOUD_RUN_SERVICE=<service name> CLOUD_RUN_REGION=<region> BUCKET_NAME=<bucket name> BQ_TABLE=<BigQuery full table name> TRIGGER_NAME=<trigger name> TRIGGER_LOCATON=<global or region>
# These next two variables rely on the above to be set PROJECT=$(gcloud config get-value project) IMAGE=gcr.io/"$PROJECT"/"$TAG_NAME":latest
Creating the Cloud Run Service
Now to create the actual Cloud Run service run the following command:
gcloud run deploy $CLOUD_RUN_SERVICE \ --region="$CLOUD_RUN_REGION" --tag "$IMAGE" \ --platform managed \ --set-env-vars=BUCKET="$BUCKET",BIGQUERY_TABLE="$BQ_TABLE"
This may take up to 5 minutes to run using the bare-bones image provided on GitHub.
Once the Cloud Run service has been created, next create the Eventarc trigger that attaches to it:
gcloud eventarc triggers create "$TRIGGER_NAME" \ --location="$TRIGGER_LOCATON" \ --destination-run-service "$CLOUD_RUN_SERVICE" \ --matching-criteria type=google.cloud.audit.log.v1.written \ --matching-criteria methodName=storage.objects.create \ --matching-criteria serviceName=storage.googleapis.com
Note: In the future when the specific resource functionality is implemented, the following command should be used instead:
gcloud eventarc triggers create "$TRIGGER_NAME" \ --location="$TRIGGER_LOCATON" \ --destination-run-service "$CLOUD_RUN_SERVICE" \ --matching-criteria type=google.cloud.audit.log.v1.written \ --matching-criteria methodName=storage.objects.create \ --matching-criteria serviceName=storage.googleapis.com \ --matching-criteria resourceName=projects/_/buckets/"$BUCKET_NAME"
Security Note: As I mentioned above, I am using the Compute Engine default service account here on both the Cloud Run service and the Eventarc trigger creation for simplicity's sake as it defaults to this. To change this for a production environment use the service-account flag on both the gcloud run and gcloud eventarc commands. To read more on this and other arguments you might want to use run the following commands:
gcloud run deploy --help gcloud eventarc triggers create --help
Testing the Setup
This is a very easy part here. I have even included a very simple test CSV file for testing on this.
Note: If you are using my sample file then make sure the table you specified in your environment variable doesn’t exist in BigQuery already. Otherwise, it might cause a load job error because the schemas will more-than-likely not match.
In your Cloud Shell (or terminal) cd into the eventarc directory where the GitHub code was checked out. Then run the following command:
gsutil cp sample-bq-load.csv gs://"$BUCKET"/
This will copy the file up into your bucket and should kick off the trigger and whole process.
Verifying Your Result
On the Cloud Run service page if you click the Triggers tab and look for your trigger you crated, about 20 seconds after running the command you should see a chart showing some invocations such as the one below.
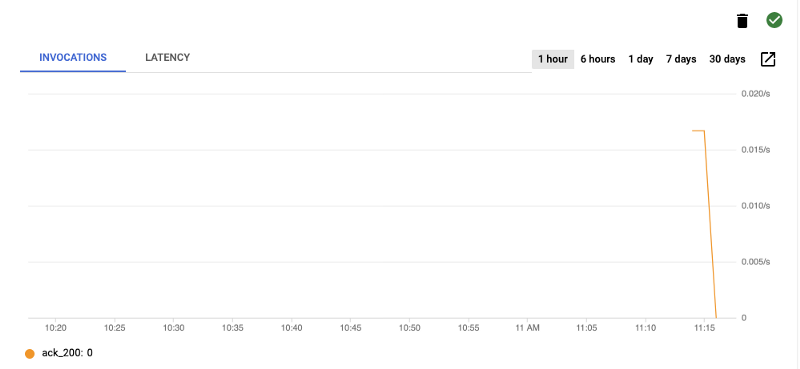
If you go into the BigQuery section of your GCP Console and navigate to the project and dataset. On the Preview tab, it should show data has been inserted such as below using the sample data. You can also look at the Details tab and see the last modified date for your table which should correlate to the last trigger run from your graph.
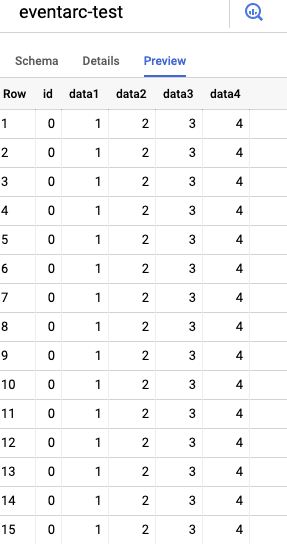
Make sure you delete this table after testing with this data and before using real data!
In Case of Error
If data is not appearing go into your Cloud Run service and click the Logs tab.
If you see a POST 500 error record in your logs then look around it to see if there are any error rows. Most will say something along the lines of ERROR in app: Exception on / [POST] followed by a Traceback of the python code in the next log record. This usually contains the error that occurred.
If it is showing a POST 200 record, but the data isn’t being loaded into BigQuery look in the logs for a reason why. The code will print out a message if the file isn’t a CSV or an environment variable is set incorrectly.



